

As more startups collect data at an earlier stage, many companies are thinking about their analytics stack earlier in their life cycle. How to set up your data stack is a common question for early-stage companies. This is understandable, as most early-stage companies rely on analysis to gather insights to help them grow and these insights depend on clean and accessible analytics.
For those that don't have enough time to read through the article, here's a quick summary of the steps that teams should take:
- Pick a cloud data warehouse. We recommend Amazon Redshift.
- Choose an ETL tool to move data into the cloud warehouse. We recommend using Airbyte to save money.
- Start using a BI/analytics tool that can visualize the data. We recommend using Redash.
- Model the data using dbt, Dataform or another modelling tool. We recommend using dbt.
- Start documenting and managing data using a data management tool. We're biased about managing your data but would recommend Secoda.
Through the article, we highlight the different options small teams should consider at each step. For analysts to deliver value through analytics, a data infrastructure needs to be built first. A good modern data stack should consider scalability that can grow as the company collects more data from multiple data sources. It should also consider end-users of the data beyond the data team and choose tools that focus on ease of use for data consumers. All employees need to have access to critical business information, which requires more thoughtful tools that are built with collaboration in mind.
No matter the company size, teams can benefit from having a cloud warehouse solution that pulls in multiple data sources using an ETL. In its simplest form, this data could be presented to business teams using analytics or BI platform. Small teams tend to focus on plug-and-play solutions for their analytics like Mixpanel or Amplitude. These tools are perfect for self-service and simple visualization but can get expensive and rigid as teams scale. Unlike plug-and-play solutions, a modern data stack is designed to quickly integrate new sources as you scale. This flexibility prevents technical debt by giving teams the ability to swap tools when limited by what they can do with their data.
What Are the Benefits of Setting Up a Modern Data Stack?
Early-stage companies don’t have the same luxury as larger teams with funding. Startups need to have clear metrics that can help them prioritize where to invest their next dollar. This means that the data stack should be simple to set up, easy to understand and affordable. It should also deliver accurate growth, product and financial metrics. Without the proper infrastructure for these metrics, answering questions can become time-consuming for data folks.
Without a centralized repository of data collected in a warehouse, teams would quickly find that financial metrics tracked in excel or google sheets have inconsistencies with the Stripe results, which causes everyone to have different understandings of the data.
This is even more difficult when stitching together growth reports or revenue forecasts that require data from multiple sources. Without the right infrastructure in place, this can be time-consuming and a manual process that requires business leaders to lose time on inefficient solutions. Adopting a modern data stack should help fix this problem by standardizing the team's understanding of the data.
One additional benefit of setting up a modern data stack is that it can be done without many resources. Most companies start with a few engineers writing some simple SQL queries against their application database. This early stage is sufficient for companies without much data or many employees. These early stages start to break down as:
- More data is collected from multiple sources
- The number of employees grows rapidly
As businesses scale, the data collection starts to include more sources like Hubspot, Heap Analytics, Google Analytics, Stripe, and Salesforce. What started as simple SQL queries can grow into a complicated data architecture once the amount of data sources grows.
5 Steps to Set Up a Modern Data Stack
When more employees join the business, most businesses grow out of the first phase of analytics and into the second stage. During this stage, more users from other lines of business need access to the information so they can make decisions quickly and understand the health of the company and the customer base. Setting up a modern data stack allows data folks to pick the best tools for both technical and non-technical folks. Modern data stack consists of a data warehouse, a data pipeline tool, a data visualization tool, a transformation tool and a data management tool. As end-users request to analyze different lines of business, data teams can plug data into the visualization tools that allow them to visualize the business through a simple interface. By centralizing all the data in a warehouse and delivering it to the business team in a BI tool, companies can be confident that the important and varied data can be captured, stored, and efficiently analyzed by all members of the team.
- The first choice that a team has to make is their data warehouse. Below we will take a look at the popular options for startups. The three primary options most companies consider are Redshift, BigQuery, and Snowflake.
- The second choice that needs to be made is the data pipeline tool. The tools we will cover are Stitch, Fivetran, and Airbyte. The pipeline services ensure that the data is delivered to the data warehouse correctly and with minimal effort.
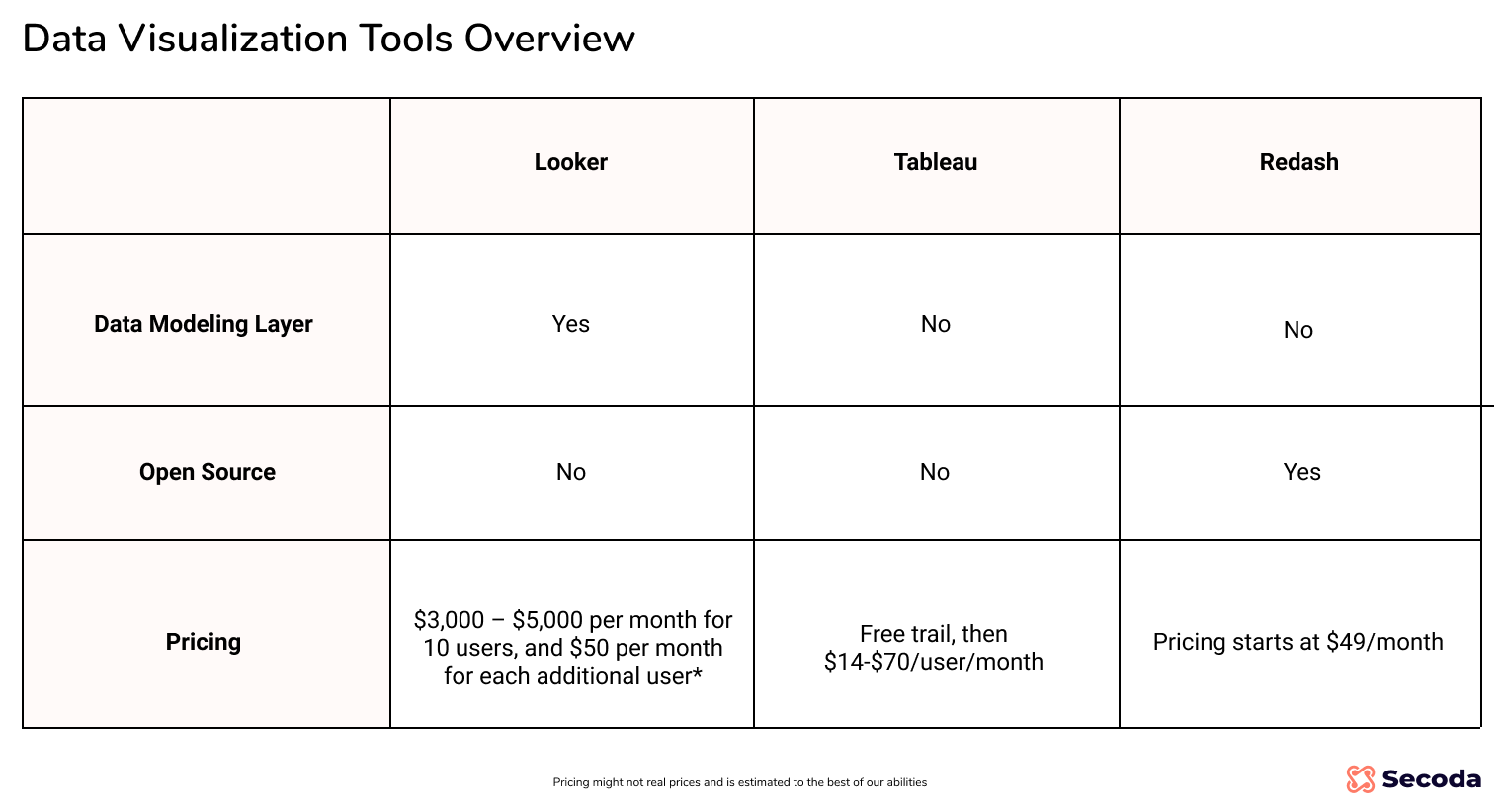
- The third choice, teams need to make is their BI and analytics tool. The options we will cover are Redash, Looker, and Tableau. This component is an important link between the data science team and the data consumers of the organization.
- The fourth choice is around the modelling layer of the data stack. Tools like dbt and Datafold are commonly used in this part of the data stack.
- Lastly, we will cover our thoughts about the forgotten fifth step, managing your data. We believe that management tools should be considered critical when starting the modern data stack. We highlight Amundsen, Secoda and Collibra in this section.
To help you set up your data stack, we’ve created a step-by-step guide with tool recommendations. We’ll review options for cloud-based warehouses, pipeline tooling, BI tools, and some other important considerations.
Step 1: Set Up Your Cloud-Based Warehouse
The central part of the modern data stack is the cloud warehouse. Before cloud-based solutions existed, organizations would spend a significant amount of time and resources to set up an environment to store and analyze data. When data needs became more complex, organizations would spend time trying to manage this environment. With cloud-based solutions, many of these performance and scaling details are configured through an admin dashboard, which can be set up with little involvement from engineers. Some of the popular options include Redshift, BigQuery and Snowflake. Each of these tools has several beneficial characteristics, some of which are highlighted below. For a more detailed analysis of cloud warehouses, you can view this article.
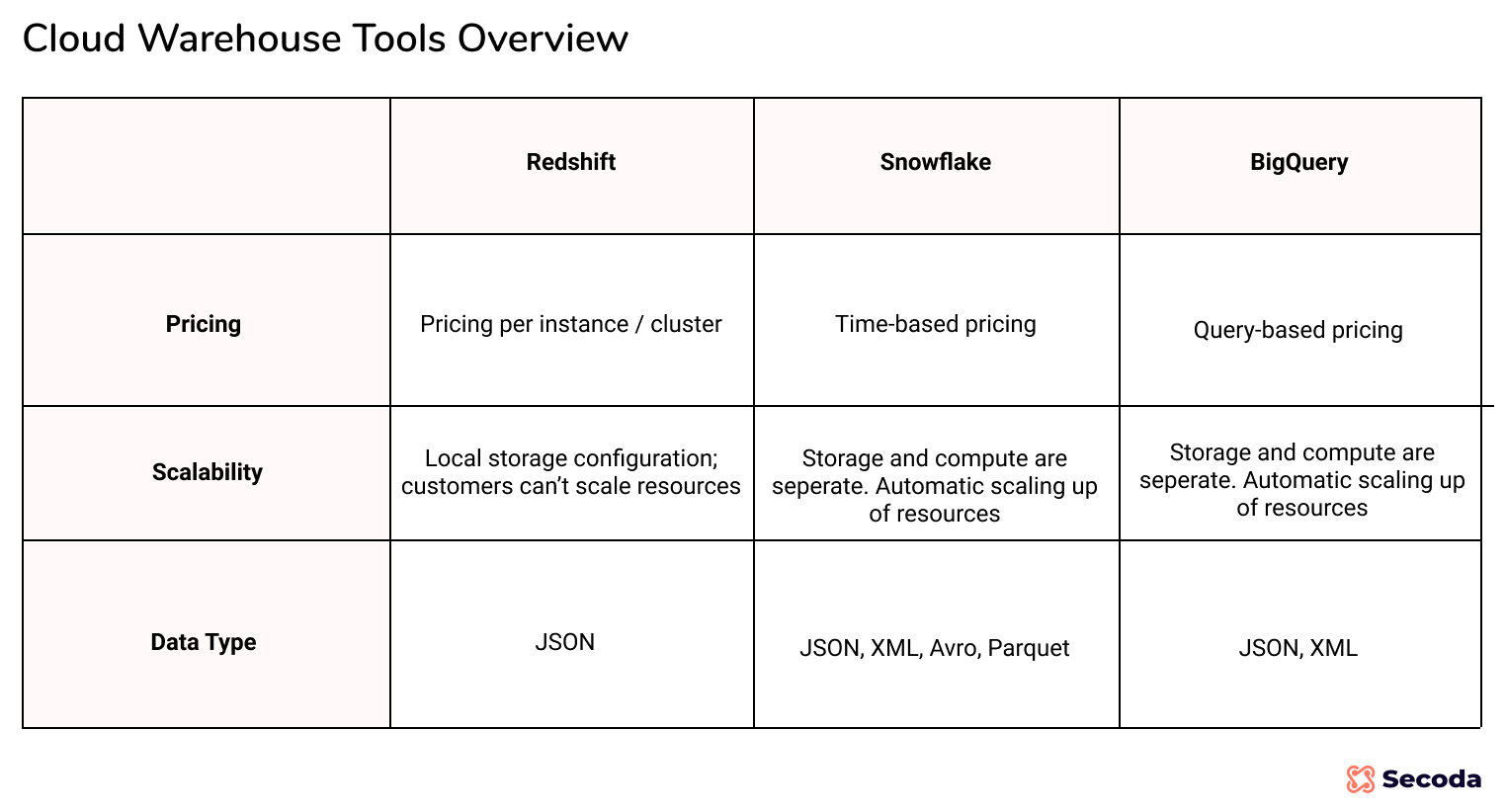
Although the cloud data warehouse is powerful, it’s not a replacement for operational databases such as PostgresSQL or MySQL. Instead, they are designed for warehousing and analyzing large amounts of data. All three solutions highlighted have flexible pricing that allows you to manage the cost structure as you scale. They also all can integrate with third-party support that can enhance the tools. Lastly, they are SQL-first platforms that are built to query your database with the same query language you are likely comfortable using.
Once teams choose their data warehouse, it’s simple to set up a new integration into the warehouse. Once a team has been set up in Redshift, any new database can be set up using a simple admin configuration screen. One additional benefit to choosing Redshift is the amount of credits that they provide startups. Although this setup period can be daunting, these options can be updated as needs change and don’t lock you into any long-term commitments. An important consideration is how well the cloud warehouse integrates with other services. Setting up a database is not extremely useful if the team is not able to get data into the system. The fortunate thing is that most of these vendors are large and established enough that most databases integrate with them. We’ll go over the integrations in our next step.
Step 2: Integrate Your Data
Once your data warehouse has been set up, you will need to load data to the warehouse from multiple sources. Although most warehouse solutions support customer loading, looking into scalable ways to easily load diverse data can save you time in the long run. We recommend choosing a data pipeline management solution that captures your data from your SaaS apps and stores it in your warehouse. Airbyte is a new, open-source tool in the pipeline space that focuses on the long tail of SaaS apps. This means that they have countless integrations that don’t require much manual configuration. Other options include Fivetran or Stitch. In addition to capturing data using Fivetran, many organizations also capture application-level data using Segment.

Step 3: Analyzing Your Data
Once the data is available, teams should decide which tool they want to use to analyze the data. Teams who want to use Looker or Tableau need to model their data before doing analysis. Working with modelled data is generally best practice, as it helps teams work off of consistent information. That being said, working with modelled data can have its drawbacks for teams who want to conduct exploratory analysis. Mode is an option for teams who don’t want to model their data in their BI tool and prefer to move quickly towards final visualizations. The options for teams are discussed in the following section. Storing the data modelling layer alongside the BI layer could limit the viability of certain “un-modelled” parts of the business. An additional consideration for teams is the cost of this layer. Solutions can become expensive quickly and startups should try to reduce costs wherever possible.
Step 4: Modelling Your Data
One of the final steps that teams should take is to add a modelling layer to their business logic. Teams can choose to model the data in a tool that is part of the visualization layer using Looker, or separately in a modelling tool that works with any visualization tool. The benefit of keeping your models outside of the BI tool is that the modelled data can be accessed by all the other tools that might require it. dbt, Dataform and airflow are popular options for modelling your data. Dataform and dot have a managed service option, while dbt also supplements this with an active Slack community. Both tools are SQL-focused and enable analysts to model and transform their data directly in their data warehouse. Many data companies also use Airflow, which is an open-source technology that was developed by engineers at Airbnb. This tool can be used for transformations but is mostly used as an orchestration tool. The last portion of the modern data stack is the data management tool, which we discuss in the following section.

Step 5: Managing Your Data
The last step of the modern data stack is finding a way to manage your data. Today, most teams use Confluence or Google docs to manage a repository of definitions and dependencies between the datasets. This process works but is not the most efficient way to manage your data. Additionally, there is very little that most teams are doing to govern access to their data. We believe this step will become more commonplace as more organizations finish the first few steps of building a modern data stack. Today, most analysts and engineers don't have a good way to understand the relationships between their datasets. This means that they rarely know what data can be deleted without affecting their models in dbt or dashboards or what tables/columns are commonly used together. They also don't know when the schema is changed, meaning that most of the time, documentation is kept outdated.
The broader category these problems fit into is data governance. This category would include the analyst's ability to discover data assets, viewing lineage information, managing accessibility, and just generally providing data consumers with the context needed to find what they are looking for. There are a few expensive, enterprise products in the space (Collibra, Alation, Informatica) and some open source options. The enterprise tools are complex and focus on the enterprise buyer. Because of this, they haven't seen broad adoption across the data stack. The open-source options are a good alternative but require consistent maintenance. An affordable and easy-to-use data governance tool will be a need to have a product for data teams and are trying to build this layer of the modern data stack at Secoda.

Conclusion
By creating the modern data stack, data teams can spend more time analyzing their data and less time engineering their data processing pipelines. Our next post will focus on the future of the data analytics space.
Try Secoda for Free
Secoda is the homepage for your data to help you to quickly and easily find the data you need. It provides a single source of truth that your teams can trust, and lets you quickly search and filter data sources. With Secoda, you can easily access, organize, and share data across all relevant stakeholders. It also helps growth and data teams to stay organized and ensure they're using the most up-to-date data. If you're interested in trying Secoda to tie your data stack together, you can reach our team at hello@secoda.co





